Анализ robots.txt и sitemap.xml
Задача этой части аудита — отловить противоречия между картой сайта, robots.txt и реальными посадочными страницами. Зачем это нужно? Например, для определения некорректного robots.txt, который скрывает от поиска важные страницы.
Пример построения отчета:
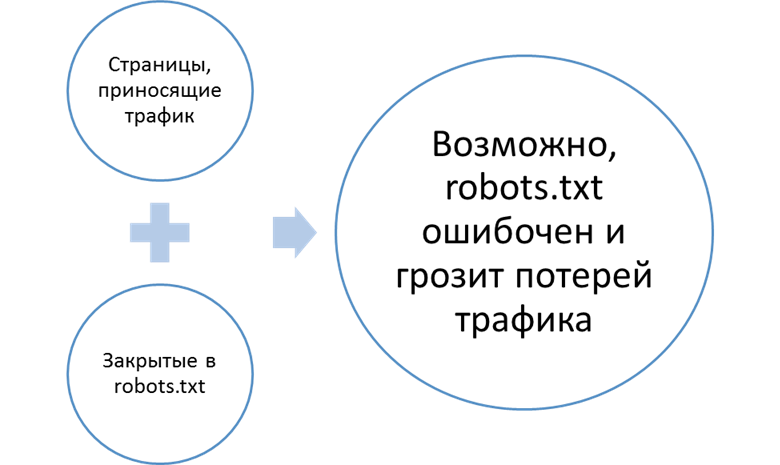
Другой пример:
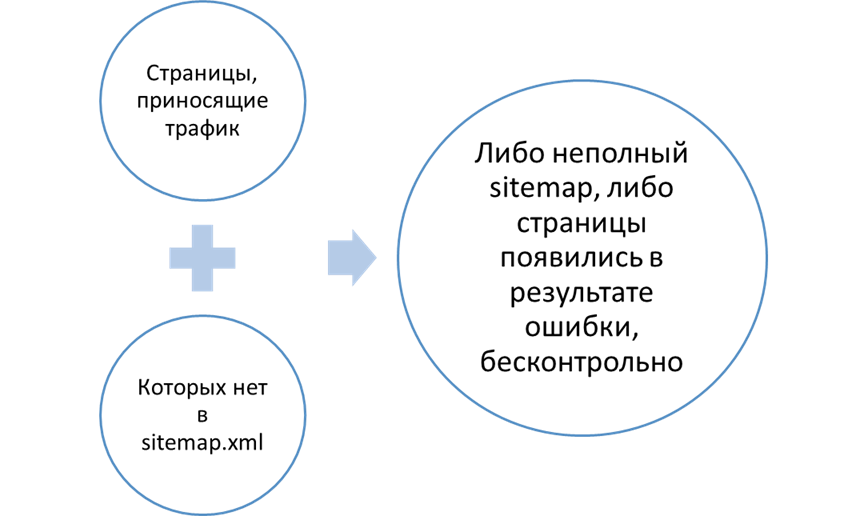
Таким образом, благодаря этой группе отчетов можно отловить:
- Ошибки в создании sitemap.xml.
- Ошибки в составлении robots.txt.
- Генерацию ненужных страниц, которые не содержат ценного контента (это может происходить как по ошибке разработчика, так и вследствие взлома сайта).
Поиск проблемных страниц
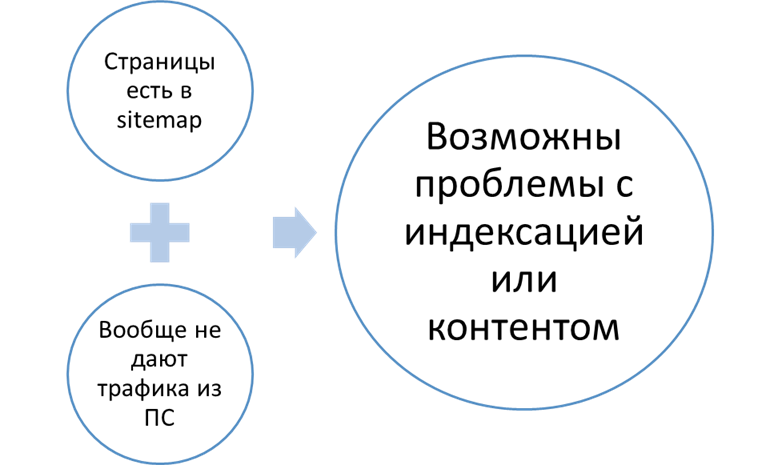
В этот отчет выводятся два типа проблемных страниц:
- Дающие статистически значимый трафик из Яндекса, но вообще не приносящие посетителей из Google и наоборот.
- Перечисленные в sitemap, но не приносящие посетителей из Яндекса, Google, или вообще ниоткуда:
Определение внутренней конкуренции
Третья часть отчета затрагивает вопросы логической структуры сайта, адекватности распределения контента по нему. Здесь отображаются ключевые слова, дающие трафик сразу на несколько страниц.
Зачем это нужно? Все просто. Внутренняя конкуренция обычно свидетельствует о «размазанном» по сайту контенте, нечеткой структуре, что неудобно для пользователя. С точки зрения «чистой» поисковой оптимизации «неустойчивость» релевантной страницы — тоже плохо, это нарушение классической схемы «1 запрос — 1 url».
Важно: большие сайты могут содержать сотни тысяч потенциально проблемных страниц. Для них обычно требуется системное решение, а не детальная проработка каждого документа, поэтому количество строк в отчетах этого раздела ограничено 1000 url. Этого достаточно чтобы отследить основные тенденции.
